How to Identify User-Agents and IP Addresses for Blocking Bots and Crawlers
In a prior post I explained the main reasons why to block undesirable bots, scrapers and crawlers in order to prevent content stealing, malware injection, and vulnerability scanning in a website. If you haven’t read that post I encourage you to do so.
One of the solutions provided was a change to the .htaccess file to block crawlers based on User-Agent or IP Address. As a result, folks were asking me how to identify which User-Agent (UA) or IP Address to block?
I am going to walk you through the log analysis process, show you what you need to know to successfully identify User-Agents and IP addresses, and provide new solutions for blocking bad bots and crawlers.
Let's start with the information that you may already have in your Apache server.
1. Log Analysis Software
Depending on your setup, you may have access to several log analysis tools such as Webalizer, Analog Stats and Awstats. If you are using Cpanel, most likely your hosting provider offers the following options:
Unfortunately, neither Webalizer, Analog Stats nor Awstats provides accurate information about which User-Agents or IP's are creating problems. In fact, most of these web log analysis programs only show certain number of bots such as the top 40, which is very limited for our purpose.
I conducted a test with these tools in May of 2008 and these were the results:
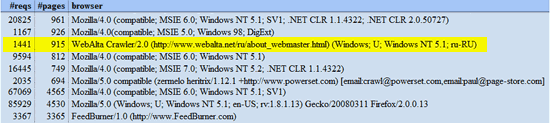
1.1. Analog Stats
Of them all, Analog Stats provided the most accurate information. Although the results were limited to only a list of the top 40 browsers sorted by the number of requests for pages. Just by looking at the list under the Total User Agents section, I spotted WebAlta, a Russian bot known for harvesting emails and scraping content for spamming and hacking purposes.
1441 915 WebAlta Crawler/2.0 (http://www.webalta.net/ru/about_webmaster.html) (Windows; U; Windows NT 5.1; ru-RU)[/code]
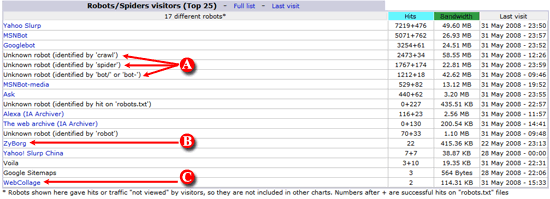
1.2. Awstats
This information was also very limited for finding bots, scrapers and crawlers. Awstats' Robots/Spider list was even smaller than the prior tool with only 17 different robots and no full identification of the User-Agent.
In fact, if you look at the 4th, 5th and 6th lines marked with an A in the image below, you will find something like "Unknown robot (identified by 'crawl', 'spider, 'bot/' or 'bot-'). Do not make any attempts to block these UAs with the .htaccess changes mentioned at the beginning. You will end up blocking Googlebot, Yahoo! Slurp or MSNbot.
The lines marked with B and C in the image below indicated a couple of robot names, but not the entire User-Agent string. That at least gave me an idea of what to look for. And since those bots did not really provide any good reasons to be in my server, I blocked them.
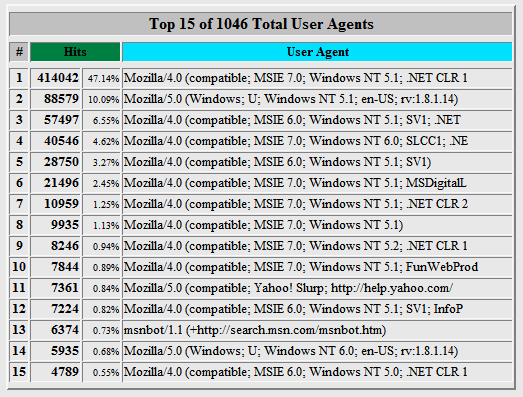
1.3 Webalizer
This log analysis tool provided information about the top 15 User-Agents based on the number of hits. According to Webalizer, there were a total of 1046 UAs identified only in May 2008. Bots and crawlers that hit the server only a few times did not appear in the list, which totally limited the analysis.
Some additional data provided by these tools is still relevant though. The number of hits, bandwidth used, most requested files and HTTP Error Codes are strong indicators of high activity that can help with discovering bad bots and crawlers. For instance, if an unknown User-Agent has been hitting a site more than a thousand times, used a lot of bandwidth, and requested Java and CSS files, then that UA might be up to something. The same goes for 403 Forbidden or 401 Unauthorized error codes. If they are high, then there is something not quite right.
2. Log Analysis Basics
2.1 User-Agent String
Every time you visit a website, your browser sends headers to the server of the site you are visiting. Each header provides specific details that will help the server retrieve the best possible information based on your request.
The User-Agent is the header that identifies the application (the browser) that is making the request from a server (website) over a network protocol (the World Wide Web). The way that HTML, Javascript and other web technologies render in a browser depend tremendously on this information. Compatibility and accessibility problems may arise if the information is poorly interpreted by the server, purposely altered (spoofing), or simply because the server is limiting access to certain users.
The User-Agent string is the text that programs use to identify themselves to HTTP, mail and news servers, for usage tracking and other purposes.
Tokens contain optional information in a User-Agent string that normally is surrounded by parentheses and varies according to each individual application. The compatibility flag ("compatible") is used by most browsers to indicate that the browser is compatible with a common set of features.
User-Agent strings look similar to these two examples:
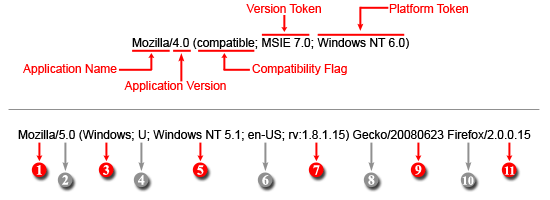
Since each section of the User-Agent string provides information about the visitor and his system, let's take a closer look at the second UA string above divided in 11 sections:
- Browser information. For historical reasons Internet Explorer identifies itself as a Mozilla 4.0 browser. Mozilla Firefox and Safari are currently using version 5.0. Other browsers like Opera also use Mozilla.
- Browser version.
- Platform:
- Windows for all Microsoft Windows environments.
- Macintosh for all MacOS environments.
- Handheld Devices.
- Linux.
- Security values:
- N for no security.
- U for strong security.
- I for weak security.
- Operating System or CPU.
- Localized language tag.
- The version of Gecko being used in the browser.
- The Gecko Engine.
- The date the browser was built.
- Browser name.
- Browser version.
For more information about User-Agent strings of specific browsers visit Mozilla, Internet Explorer, and Safari.
2.2 User-Agent and IP Address Spoofing
Depending entirely on information provided by User-Agents is not good enough to prevent scraping, email harvesting and related problems. User-Agents are easily spoofed these days, which means that anyone can name a User-Agent Googlebot, Slurp or MSNbot to access your website.
Just to give you an example, it took me less than 2 minutes to change the default User-Agent of my browser to the one showing on this image:

As you can see, I even called the User-Agent Mozilla version 5.0, but with different information for some tokens:
- Operating System or CPU: SpanishSEO.org Bot Test, which did not exist.
- Localized language tag: changed the language localization to Spanish USA when I used English.
- Browser name and version: LogZ/1.0, which did not exist.
Likewise, an IP Address can be spoofed by using proxy servers and other technologies. Even Google Language Tool was used as a proxy in International SEO to spy and access restricted websites or bypass the restrictions set in networks that limited access to specific content by location.
At the present Google Translate does not allow translations from English to English, which was the proxy method widely used. But if you translate a website from English to Spanish, you will see that what appears in your log file is Google's IP Address instead of the real visitor's IP.
To ilustrate this situation I translated LogZ Free Log Analyzer first page from English to Spanish using Google Translate.
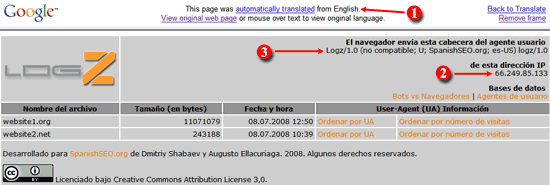
- Shows the language translation source, in this case English.
- Shows the IP Address 66.249.85.133, instead of 16.25.45.164, with the following details:
- Reverse DNS results showed ff-in-f133.google.com.
- Forward DNS results for ff-in-f133.google.com did not resolve.
- The Whois results for ff-in-f133.google.com were not found. However, the Whois lookup for IP 66.249.85.133 provided full details for Google Inc.
- The Geo IP Location for 66.249.85.133 showed:
- Address: Mountain View, California 94043, USA.
- ISP: Google Inc.
- Domain: google.com
- Shows a spoofed User-Agent.
The other way you can make this work for English content is by translating a site already in English as if it were translating from a different language, let's say Spanish. Use this code:
http://translate.google.com/translate?u=http://www.your-site-here.com/&langpair=es|en&hl=en&ie=UTF8
You will have to change http://www.your-site-here.com for the website you are targeting. "langpair=es|en" is what indicated Google to translate the content from Spanish to English.
Keep in mind that with a more sophisticated IP detection system, your IP Address will be displayed next to the transparent proxy from Google.
Similar proxy issues are seen with Yahoo Babelfish when using this code:
http://66.196.80.202/babelfish/translate_url_content?lp=es_en&url=your-site-here.com/&.intl=us
2.3 Reverse DNS, Forward DNS and Whois Lookups
If User-Agents and IP Addresses can be spoofed, then what are the best alternatives to identify undesirable bots and crawlers that were or are in a site?
One of the methods suggested in a post written by Matt Cutts titled how to verify Googlebot is to do a round trip DNS Lookup, which has two steps:
- First, you need to get the IP address of the crawler and perform a Reverse DNS Lookup to ensure that the IP Address belongs to the Search Engine domain. For example, the Reverse DNS Lookup for the IP 74.6.22.154 retrieves the Hostname llf520064.crawl.yahoo.net.
- The second step is to perform a forward DNS lookup with the Hostname to make sure that the resulting IP address matches the original. Using the same example, the Forward DNS Lookup for the Hostname llf520064.crawl.yahoo.net. retrieves the IP Address 74.6.22.154.
In addition to the Reverse and Forward DNS Lookups, you should consider a Whois Domain Name Lookup to ensure that the IP of the crawler falls within the IP range of the Search Engine. To continue using Yahoo! as an example, if you check the Yahoo! IP range at iplist.com, you will find that the IP Address 74.6.22.154 is within range.
All the main Search Engines such as Google, Yahoo!, MSN, and Ask make it easy to check if the Hostname of an IP belongs to them by including these information:
- Google crawlers will end with googlebot.com like in crawl-66-249-70-244.googlebot.com.
- Yahoo crawlers will end with crawl.yahoo.net like in llf520064.crawl.yahoo.net.
- Live Search crawlers will end with search.msn.com like in msnbot-65-55-104-161.search.msn.com.
- Ask crawlers will end with ask.com like in crawler4037.ask.com.
Make sure not to confuse the User-Agent string with the Hostname. They are two different things. However, in some cases you may find information about the crawler in the User-Agent string like in this case:
Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
In the example above, the crawler is identifying itself by providing its name and a URL where to learn more about it. Bots and crawlers that don't provide such information tend to get involved in suspicious activities. The situation gets even worse if a round trip DNS Lookup does not resolve properly. In a situation like that, it will be better to block the rogue bot.
This entire process of DNS Lookups should be done in real time and at high speed. However, doing a Reverse and Forward DNS Lookups will down slow the server tremendously. The best way to do this is by caching the Database (MySQL) and keeping the User-Agent and IP Address comparison data cached for a specific period of time. That should include all cases in which crawlers either pass the test successfully or fail.
A different alternative was proposed by Bill Atchison (a.k.a. IncrediBill), which consist of locking down the server with an opt-in type of strategy. In Bill's own words:
You can block many bots by simply changing your .htaccess files to OPT-IN instead of OPT-OUT, basically whitelisting instead of blacklisting. You let in Google, Yahoo, MSN, etc. and IE, Opera, Firefox, Netscape and bounce EVERYTHING else by default. The beauty here is you don't have to keep looking for bots anymore as anything that identifies itself as a bot will be bounced.
He continues saying "Changing to OPT-IN whitelist alone sends a lot of nonsense away, just make sure to check your log files to see where all your traffic is coming from to make sure all valid crawlers sending you traffic are whitelisted."
Bill's approach is an interesting alternative for blocking bots. However, there is a chance to block your main sources of traffic if you don't really understand the concepts needed to successfully do it.
Now that you know how to analyze server logs, recognize User-Agents, IP's and Hostnames, I have one more solution in place for you. Instead of being a cumbersome process in real time, this script focuses on post-log analysis, meaning that you can manually check the data, retrieve User-Agents and IP's from log files, do a round trip DNS Lookup with Whois and GEO IP Location included, and use that information to block undesirable bots and crawlers according to your needs. Simple as that! Want a copy? then visit the Free Log Analyzer page.










good article. I am programming a real time bot detecter. Because many of my problemes are from stealth bots. Bots with usual user-agent.
Augusto Ellacuriaga

Thanks for stopping by avanzaweb. Welcome to SpanishSEO :)
Visible bots are easier to deal with than stealth bots, but they are still beatable.
We are also testing a real time bot detector in php. Will have more details once the final testings are done.
Please let me know when you have your solution in place to check it out.
Augusto,
What’s the big deal in doing a roundup reverse and forward lookup in a possibly spoofed IP? I suppose that by reversing a faked Yahoo! IP will end up in a hostname ‘*crawl.yahoo.net’. And in the same way, by doing a forward lookup in that hostname, we’ll get the same faked Yahoo IP… right?
Maybe I missed something in the whole explanation… could you enlight me?
Tanks a lot.
Augusto Ellacuriaga
Hi Alvaro,
By doing a round trip DNS lookup you will be able to identify whether an IP, User-Agent and/or hostname are spoofed or legit. The information simply will not match across all of them and that’s your biggest evidence that something is not right and you are potentially dealing with a fake crawler.
You cannot depend on only one factor. Reverse and forward should be run together and the information compared. And if you want to add one more layer of verification, then lookup the whois information of that IP.
A spoofed bot is easy to detect based on its IP, because the hostname will not have the name of the main Search Engines or a quality website. They can call it whatever they want, but the truth is that anyone can fake the identifying information.
For instance, a bot coming from a proxy IP with a User-Agent saying that is the Yahoo! bot most likely will not reverse to crawl.yahoo.net. However, in some instances Search Engines like Yahoo also use IPs that are out of their IP range. Yahoo, Microsoft and Google are well known for using Proxy IP’s that don’t fall into their own range of IPs. In fact, if you see your logs you will probably find IPs from bots coming from Brasil, India, China that appear to belong to Google even though their User-Agents may or may not identify as belonging to Google. So if you run a reverse lookup, you can have the hostname and will be a stronger indicator that the bot, even though without proper identification, belong to the Search Engine. But this is not enough to prove that the bot indeed belongs to Google.
But what if you find unnamed bots, with no User-Agent information, from IPs that don’t fall into the IP ranges of the major Search Engines? That doesn’t necessarily mean that they are faked bots though. A reverse lookup will give you the hostname of that bot that could be xyz.crawl2.yahoo.com. And if you perform a forward DNS Lookup to that hostname, it should give you the same IP address that you originally found. Conversely, if the forward lookup gives you a different IP, then most likely you are dealing with a fake bot.
I hope this explanation helps more.
Cheers,
Ok, but what if someone simply fake the initial IP information, providing one from a trusted bot? I presume it should take us to a valid hostname, and so forward lookup will end up in the same faked yet trusted IP, right?
So the question is…. could a bot do that (fake to a trusted IP) to pass as a valid bot?
Tanks very much.
Augusto Ellacuriaga
Yes, a bot could do that!
IP spoofing happens through botnets and DoS attacks (Denial of Service attacks). However, it requires a high degree of understanding of different technologies.
In situations like that there are other things that can be implemented to further protect your site from fake bots/attacks. Packet filtering is one of them.
Augusto, thanks for the answers.
I’ve been testing reverse lookups in this Google iplist, and trying to gather the hostnames… but I found that most of those IPs have no host defined… from nearly 265 tests only three of them returned valid hosts, see:
216.239.45.4 >: 216-239-45-4.google.com
216.239.51.96 >: kc-in-f96.google.com
216.239.51.97 >: kc-in-f97.google.com
If - as you said - not always bots from a trusted source use a consistent user Agent, and if not always those bots reply to a legit hostname,could we consider practically impossible to identify the logs from the desired bots in a website? If not, what other consistent method could we use?
Augusto Ellacuriaga
Even though you may run into issues explained above, the most important bots/crawlers’ information, like Google bot coming the IP 66.249.70.244, hostname crawl-66-249-70-244.googlebot.com and identifying itself as googlebot.com, tends to remain stable. Search Engines are aware that small changes to those important bots will cause some serious headaches to webmasters.
For increased protection use a white listing method. That means that you will command your server to ONLY allow certain bots coming from a list of pre-identified IPs, hostnames and User-Agents. The rest of bots will be forbidden and will not be able to access your information. That also can be combined with a massive IP blocking from geographical areas that you are not particularly interested in targeting and that might represent a threat to your security or information.
The main drawback with the white listing method is that sometimes good sources of traffic can get blocked. Even using coffee shops’ proxies to access your site will not go through and that can cost you some traffic. Additionally, you will have to keep an eye on the changes related to bots of your interest, though this is very infrequent.



